
Hay algunos Sql Patrones que, una vez que los conoces, comienzas a verlos en todas partes. Las soluciones a los rompecabezas que le mostraré hoy son en realidad consultas SQL muy simples, pero comprender el concepto detrás de ellos seguramente desbloqueará nuevas soluciones a las consultas que escribe en el día a día.
Todos estos desafíos se basan en escenarios del mundo real, ya que en los últimos meses hice un punto de escribir cada consulta similar a un rompecabezas que tuve que construir. También te animo a que los pruebes por ti mismo, para que puedas desafiarte primero, ¡lo que mejorará tu aprendizaje!
Todas las consultas para generar los conjuntos de datos se proporcionarán en una sintaxis amigable para PostgreSQL y DuckDB, para que pueda copiar y jugar fácilmente con ellos. Al final, también le proporcionaré un enlace a un repositorio de GitHub que contenga todo el código, ¡así como la respuesta al desafío de bonificación que dejaré por usted!
Organicé estos rompecabezas en orden de creciente dificultad, por lo que, si encuentras los primeros demasiado fáciles, al menos eche un vistazo a la última, que utiliza una técnica que realmente creo que no habrás visto antes.
Bien, comencemos.
Me encanta este rompecabezas debido a lo corta y simple que es la consulta final, a pesar de que se ocupa de muchos casos de borde. Los datos para este desafío muestran que los boletos se mueven entre las etapas de Kanban, y el objetivo es encontrar cuánto tiempo, en promedio, los boletos permanecen en la etapa de hacer.
Los datos contienen la identificación del boleto, la fecha en que se creó el boleto, la fecha de la mudanza y las etapas “de” y “a” de la mudanza. Las etapas presentes son nuevas, haciendo, revisión y realizada.
Algunas cosas que necesita saber (casos de borde):
- Los boletos pueden avanzar hacia atrás, lo que significa que los boletos pueden volver a la etapa de hacer.
- No debe incluir boletos que aún estén atascados en la etapa de hacer, ya que no hay forma de saber cuánto tiempo permanecerán allí.
- Los boletos no siempre se crean en la nueva etapa.
CREATE TABLE ticket_moves (
ticket_id INT NOT NULL,
create_date DATE NOT NULL,
move_date DATE NOT NULL,
from_stage TEXT NOT NULL,
to_stage TEXT NOT NULL
);
INSERT INTO ticket_moves (ticket_id, create_date, move_date, from_stage, to_stage)
VALUES
-- Ticket 1: Created in "New", then moves to Doing, Review, Done.
(1, '2024-09-01', '2024-09-03', 'New', 'Doing'),
(1, '2024-09-01', '2024-09-07', 'Doing', 'Review'),
(1, '2024-09-01', '2024-09-10', 'Review', 'Done'),
-- Ticket 2: Created in "New", then moves: New → Doing → Review → Doing again → Review.
(2, '2024-09-05', '2024-09-08', 'New', 'Doing'),
(2, '2024-09-05', '2024-09-12', 'Doing', 'Review'),
(2, '2024-09-05', '2024-09-15', 'Review', 'Doing'),
(2, '2024-09-05', '2024-09-20', 'Doing', 'Review'),
-- Ticket 3: Created in "New", then moves to Doing. (Edge case: no subsequent move from Doing.)
(3, '2024-09-10', '2024-09-16', 'New', 'Doing'),
-- Ticket 4: Created already in "Doing", then moves to Review.
(4, '2024-09-15', '2024-09-22', 'Doing', 'Review');Un resumen de los datos:
- Boleto 1: Creado en la nueva etapa, se mueve normalmente a hacer, luego revise y luego se realiza.
- Boleto 2: Creado en nuevo, luego movimientos: Nuevo → Hacer → Revisión → Hacer de nuevo → Revisión.
- Boleto 3: Creado en nuevos movimientos a hacer, pero todavía está atascado allí.
- Boleto 4: Creado en la etapa de hacer, se mueve para revisar después.
Puede ser una buena idea detenerse un poco y pensar cómo lidiaría con esto. ¿Puedes averiguar cuánto tiempo permanece un boleto en una sola etapa?
Honestamente, esto suena intimidante al principio, y parece que será una pesadilla lidiar con todos los casos de borde. Déjame mostrarte la solución completa al problema, y luego explicaré lo que está sucediendo después.
WITH stage_intervals AS (
SELECT
ticket_id,
from_stage,
move_date
- COALESCE(
LAG(move_date) OVER (
PARTITION BY ticket_id
ORDER BY move_date
),
create_date
) AS days_in_stage
FROM
ticket_moves
)
SELECT
SUM(days_in_stage) / COUNT(DISTINCT ticket_id) as avg_days_in_doing
FROM
stage_intervals
WHERE
from_stage = 'Doing';

El primer CTE utiliza la función de retraso para encontrar el movimiento anterior del boleto, que será el momento en que el boleto ingresó a esa etapa. Calcular la duración es tan simple como restar la fecha anterior desde la fecha de movimiento.
Lo que debe notar es el uso de la Counsce en la fecha de mudanza anterior. Lo que eso hace es que si un boleto no tiene un movimiento anterior, entonces usa la fecha de creación del boleto. Esto se encarga de los casos de boletos que se crean directamente en la etapa de hacer, ya que aún calculará adecuadamente el tiempo que llevó abandonar el escenario.
Este es el resultado del primer CTE, que muestra el tiempo que pasa en cada etapa. Observe cómo el boleto 2 tiene dos entradas, ya que visitó la etapa de hacer en dos ocasiones separadas.

Con esto hecho, es solo una cuestión de obtener el promedio, ya que la suma de los días totales pasados en hacer, dividido por el distintivo número de boletos que alguna vez abandonaron el escenario. Hacerlo de esta manera, en lugar de simplemente usar el AVG, se asegura de que las dos filas para Ticket 2 se contabilicen correctamente como un solo boleto.
No es tan malo, ¿verdad?
El objetivo de este segundo desafío es Encuentre la secuencia de contrato más reciente de cada empleado. Un descanso de secuencia ocurre cuando dos contratos tienen una brecha de más de un día entre ellos.
En este conjunto de datos, no hay superposiciones de contrato, lo que significa que un contrato para el mismo empleado tiene una brecha o termina un día antes de que comience el nuevo.
CREATE TABLE contracts (
contract_id integer PRIMARY KEY,
employee_id integer NOT NULL,
start_date date NOT NULL,
end_date date NOT NULL
);
INSERT INTO contracts (contract_id, employee_id, start_date, end_date)
VALUES
-- Employee 1: Two continuous contracts
(1, 1, '2024-01-01', '2024-03-31'),
(2, 1, '2024-04-01', '2024-06-30'),
-- Employee 2: One contract, then a gap of three days, then two contracts
(3, 2, '2024-01-01', '2024-02-15'),
(4, 2, '2024-02-19', '2024-04-30'),
(5, 2, '2024-05-01', '2024-07-31'),
-- Employee 3: One contract
(6, 3, '2024-03-01', '2024-08-31');
Como resumen de los datos:
- Empleado 1: Tiene dos contratos continuos.
- Empleado 2: Un contrato, luego una brecha de tres días, luego dos contratos.
- Empleado 3: Un contrato.
El resultado esperado, dado el conjunto de datos, es que todos los contratos deben incluirse, excepto el primer contrato del Empleado 2, que es el único que tiene una brecha.
Antes de explicar la lógica detrás de la solución, me gustaría que piense en qué operación se puede usar para unir los contratos que pertenecen a la misma secuencia. Concéntrese solo en la segunda fila de datos, ¿qué información necesita saber si este contrato fue un descanso o no?
Espero que esté claro que esta es la situación perfecta para las funciones de la ventana, nuevamente. Son increíblemente útiles para resolver problemas como este, y comprender cuándo usarlos ayuda mucho a encontrar soluciones limpias para los problemas.
Lo primero que debe hacer, entonces, es obtener la fecha de finalización del contrato anterior para el mismo empleado con la función LAG. Al hacer eso, es simple comparar ambas fechas y verificar si fue un descanso de secuencia.
WITH ordered_contracts AS (
SELECT
*,
LAG(end_date) OVER (PARTITION BY employee_id ORDER BY start_date) AS previous_end_date
FROM
contracts
),
gapped_contracts AS (
SELECT
*,
-- Deals with the case of the first contract, which won't have
-- a previous end date. In this case, it's still the start of a new
-- sequence.
CASE WHEN previous_end_date IS NULL
OR previous_end_date < start_date - INTERVAL '1 day' THEN
1
ELSE
0
END AS is_new_sequence
FROM
ordered_contracts
)
SELECT * FROM gapped_contracts ORDER BY employee_id ASC;

Una forma intuitiva de continuar la consulta es numerar las secuencias de cada empleado. Por ejemplo, un empleado que no tiene brecha siempre estará en su primera secuencia, pero un empleado que tuvo 5 descansos en contratos estará en su quinta secuencia. Curiosamente, esto se hace por otra función de ventana.
--
-- Previous CTEs
--
sequences AS (
SELECT
*,
SUM(is_new_sequence) OVER (PARTITION BY employee_id ORDER BY start_date) AS sequence_id
FROM
gapped_contracts
)
SELECT * FROM sequences ORDER BY employee_id ASC;
Observe cómo, para el empleado 2, comienza su secuencia #2 después del primer valor expulsado. Para terminar esta consulta, agrupé los datos por empleado, obtuve el valor de su secuencia más reciente y luego hice una unión interna con las secuencias para mantener solo la más reciente.
--
-- Previous CTEs
--
max_sequence AS (
SELECT
employee_id,
MAX(sequence_id) AS max_sequence_id
FROM
sequences
GROUP BY
employee_id
),
latest_contract_sequence AS (
SELECT
c.contract_id,
c.employee_id,
c.start_date,
c.end_date
FROM
sequences c
JOIN max_sequence m ON c.sequence_id = m.max_sequence_id
AND c.employee_id = m.employee_id
ORDER BY
c.employee_id,
c.start_date
)
SELECT
*
FROM
latest_contract_sequence;
Como se esperaba, nuestro resultado final es básicamente nuestra consulta inicial solo con el primer contrato del empleado 2 que falta.
Finalmente, el último rompecabezas: me alegra que hayas llegado tan lejos.
Para mí, esta es la más alucinante, ya que cuando encontré este problema por primera vez pensé en una solución completamente diferente que sería un desastre en SQL.
Para este rompecabezas, he cambiado el contexto de lo que tuve que lidiar para mi trabajo, ya que creo que facilitará la explicación.
Imagine que es analista de datos en un lugar de eventos, y está analizando las conversaciones programadas para un próximo evento. Desea encontrar la hora del día en la que se realizará el mayor número de conversaciones al mismo tiempo.
Esto es lo que debe saber sobre los horarios:
- Las habitaciones se reservan en incrementos de 30 minutos, por ejemplo, de 9H-10H30.
- Los datos están limpios, no hay libres de salas de reuniones.
- Puede haber reuniones consecutivas en una sola sala de reuniones.

Programa de reuniones visualizado (estos son los datos reales).
CREATE TABLE meetings (
room TEXT NOT NULL,
start_time TIMESTAMP NOT NULL,
end_time TIMESTAMP NOT NULL
);
INSERT INTO meetings (room, start_time, end_time) VALUES
-- Room A meetings
('Room A', '2024-10-01 09:00', '2024-10-01 10:00'),
('Room A', '2024-10-01 10:00', '2024-10-01 11:00'),
('Room A', '2024-10-01 11:00', '2024-10-01 12:00'),
-- Room B meetings
('Room B', '2024-10-01 09:30', '2024-10-01 11:30'),
-- Room C meetings
('Room C', '2024-10-01 09:00', '2024-10-01 10:00'),
('Room C', '2024-10-01 11:30', '2024-10-01 12:00');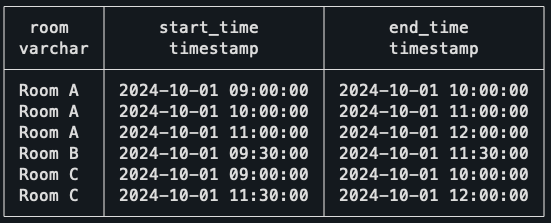
La forma de resolver esto es usar lo que se llama algoritmo de línea de barrido, o también conocido como solución basada en eventos. Este apellido en realidad ayuda a comprender lo que se hará, ya que la idea es que en lugar de tratar con intervalos, que es lo que tenemos en los datos originales, tratamos con eventos.
Para hacer esto, necesitamos transformar cada fila en dos eventos separados. El primer evento será el comienzo de la reunión, y el segundo evento será el final de la reunión.
WITH events AS (
-- Create an event for the start of each meeting (+1)
SELECT
start_time AS event_time,
1 AS delta
FROM meetings
UNION ALL
-- Create an event for the end of each meeting (-1)
SELECT
-- Small trick to work with the back-to-back meetings (explained later)
end_time - interval '1 minute' as end_time,
-1 AS delta
FROM meetings
)
SELECT * FROM events;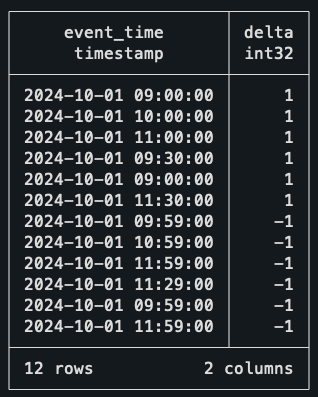
Tómese el tiempo para comprender lo que está sucediendo aquí. Para crear dos eventos a partir de una sola fila de datos, simplemente estamos unir el conjunto de datos en sí mismo; La primera mitad usa la hora de inicio como marca de tiempo, y la segunda parte usa la hora de finalización.
Es posible que ya note la columna delta creada y vea a dónde va esto. Cuando comienza un evento, lo contamos como +1, cuando termina, lo contamos como -1. Incluso es posible que ya esté pensando en otra función de ventana para resolver esto, ¡y tiene razón!
Pero antes de eso, permítanme explicar el truco que usé en las fechas finales. Como no quiero que las reuniones consecutivas cuenten como dos reuniones concurrentes, estoy restando un solo minuto de cada fecha de finalización. De esta manera, si una reunión termina y otra comienza a las 10h30, no se supondrá que dos reuniones ocurran simultáneamente a las 10h30.
Bien, volvamos a la consulta y otra función de la ventana. Esta vez, sin embargo, la función de elección es una suma rodante.
--
-- Previous CTEs
--
ordered_events AS (
SELECT
event_time,
delta,
SUM(delta) OVER (ORDER BY event_time, delta DESC) AS concurrent_meetings
FROM events
)
SELECT * FROM ordered_events ORDER BY event_time DESC;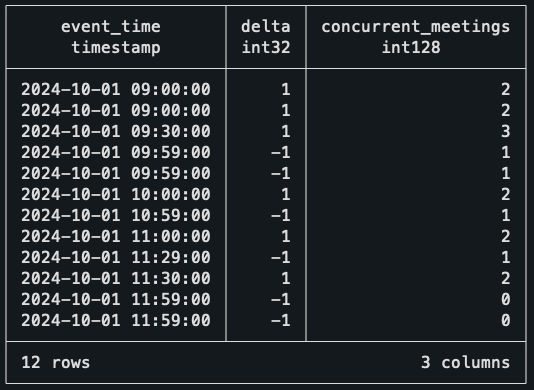
La suma rodante en la columna delta esencialmente camina por cada registro y encuentra cuántos eventos están activos en ese momento. Por ejemplo, a las 9 am agudas, ve que dos eventos comienzan, por lo que marca el número de reuniones concurrentes como dos.
Cuando comienza la tercera reunión, el conteo sube a tres. Pero cuando llega a las 9h59 (10 a.m.), luego dos reuniones terminan, llevando el mostrador a uno. Con estos datos, lo único que falta es encontrar cuándo ocurre el mayor valor de las reuniones concurrentes.
--
-- Previous CTEs
--
max_events AS (
-- Find the maximum concurrent meetings value
SELECT
event_time,
concurrent_meetings,
RANK() OVER (ORDER BY concurrent_meetings DESC) AS rnk
FROM ordered_events
)
SELECT event_time, concurrent_meetings
FROM max_events
WHERE rnk = 1;
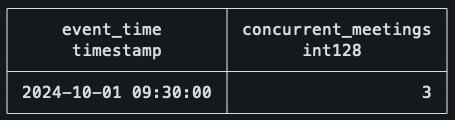
¡Eso es todo! ¡El intervalo de 9h30-10h es el que tiene el mayor número de reuniones concurrentes, que se verifica con la visualización del horario anterior!
Esta solución se ve increíblemente simple en mi opinión, y funciona para muchas situaciones. Cada vez que se trata de intervalos ahora, debe pensar si la consulta no sería más fácil si lo pensara en la perspectiva de los eventos.
Pero antes de seguir adelante, y para realmente clavar este concepto, quiero dejarte con un desafío de bonificación, que también es una aplicación común del Algoritmo de línea de barrido. ¡Espero que lo pruebes!
Desafío de bonificación
El contexto para este sigue siendo el mismo que el último rompecabezas, pero ahora, en lugar de tratar de encontrar el período en que hay más reuniones concurrentes, el objetivo es encontrar una mala programación. Parece que hay superposiciones en las salas de reuniones, que deben enumerarse para que se pueda solucionar lo antes posible.
¿Cómo descubriría si la misma sala de reuniones tiene dos o más reuniones reservadas al mismo tiempo? Aquí hay algunos consejos sobre cómo resolverlo:
- Sigue siendo el mismo algoritmo.
- Esto significa que aún harás el sindicato, pero se verá ligeramente diferente.
- Deberías pensar en la perspectiva de cada sala de reuniones.
Puede usar estos datos para el desafío:
CREATE TABLE meetings_overlap (
room TEXT NOT NULL,
start_time TIMESTAMP NOT NULL,
end_time TIMESTAMP NOT NULL
);
INSERT INTO meetings_overlap (room, start_time, end_time) VALUES
-- Room A meetings
('Room A', '2024-10-01 09:00', '2024-10-01 10:00'),
('Room A', '2024-10-01 10:00', '2024-10-01 11:00'),
('Room A', '2024-10-01 11:00', '2024-10-01 12:00'),
-- Room B meetings
('Room B', '2024-10-01 09:30', '2024-10-01 11:30'),
-- Room C meetings
('Room C', '2024-10-01 09:00', '2024-10-01 10:00'),
-- Overlaps with previous meeting.
('Room C', '2024-10-01 09:30', '2024-10-01 12:00');Si está interesado en la solución a este rompecabezas, así como al resto de las consultas, verifique esto Repositorio de Github.
La primera conclusión de esta publicación de blog es que las funciones de la ventana están dominadas. Desde que me sentí más cómodo con el uso de ellos, siento que mis consultas se han vuelto mucho más simples y más fáciles de leer, y espero que te pase lo mismo.
Si está interesado en aprender más sobre ellos, probablemente disfrutará de leer Esta otra publicación de blog He escrito, donde repaso cómo puedes entender y usarlos de manera efectiva.
La segunda conclusión es que estos patrones utilizados en los desafíos realmente suceden en muchos otros lugares. Es posible que deba encontrar secuencias de suscripciones, retención de clientes, o es posible que necesite encontrar una superposición de tareas. Hay muchas situaciones en las que necesitará usar funciones de ventana de manera muy similar a lo que se hizo en los rompecabezas.
La tercera cosa que quiero que recuerdes es sobre esta solución para usar eventos además de tratar con intervalos. He visto algunos problemas que resolví hace mucho tiempo que podría haber usado este patrón para facilitar mi vida, y desafortunadamente no lo sabía en ese momento.
Realmente espero que hayas disfrutado de esta publicación y haya dado una oportunidad a los rompecabezas. ¡Y estoy seguro de que si llegó tan lejos, aprendió algo nuevo sobre SQL o fortaleció su conocimiento de las funciones de la ventana!
Muchas gracias por leer. Si tiene preguntas o simplemente desea ponerse en contacto conmigo, no dude en ponerse en contacto conmigo mtrentz.com.
Todas las imágenes del autor a menos que se indique lo contrario.