
Introducción
La serie Falcon-H1, desarrollada por el Technology Innovation Institute (TII), marca un avance significativo en la evolución de los modelos de idiomas grandes (LLM). Al integrar la atención basada en transformadores con los modelos de espacio de estado basados en Mamba (SSMS) en una configuración paralela híbrida, Falcon-H1 logra un rendimiento excepcional, eficiencia de la memoria y escalabilidad. Lanzado en múltiples tamaños (parámetros de 0.5B a 34B) y versiones (Base, Instrucciones ajustadas y cuantificadas), los modelos Falcon-H1 redefinen la compensación entre el presupuesto de cálculo y la calidad de la salida, ofreciendo una eficiencia de los parámetros superiores a muchos modelos contemporáneos como QWEN2.5-72B y Llama3.3-70B.
Innovaciones arquitectónicas clave
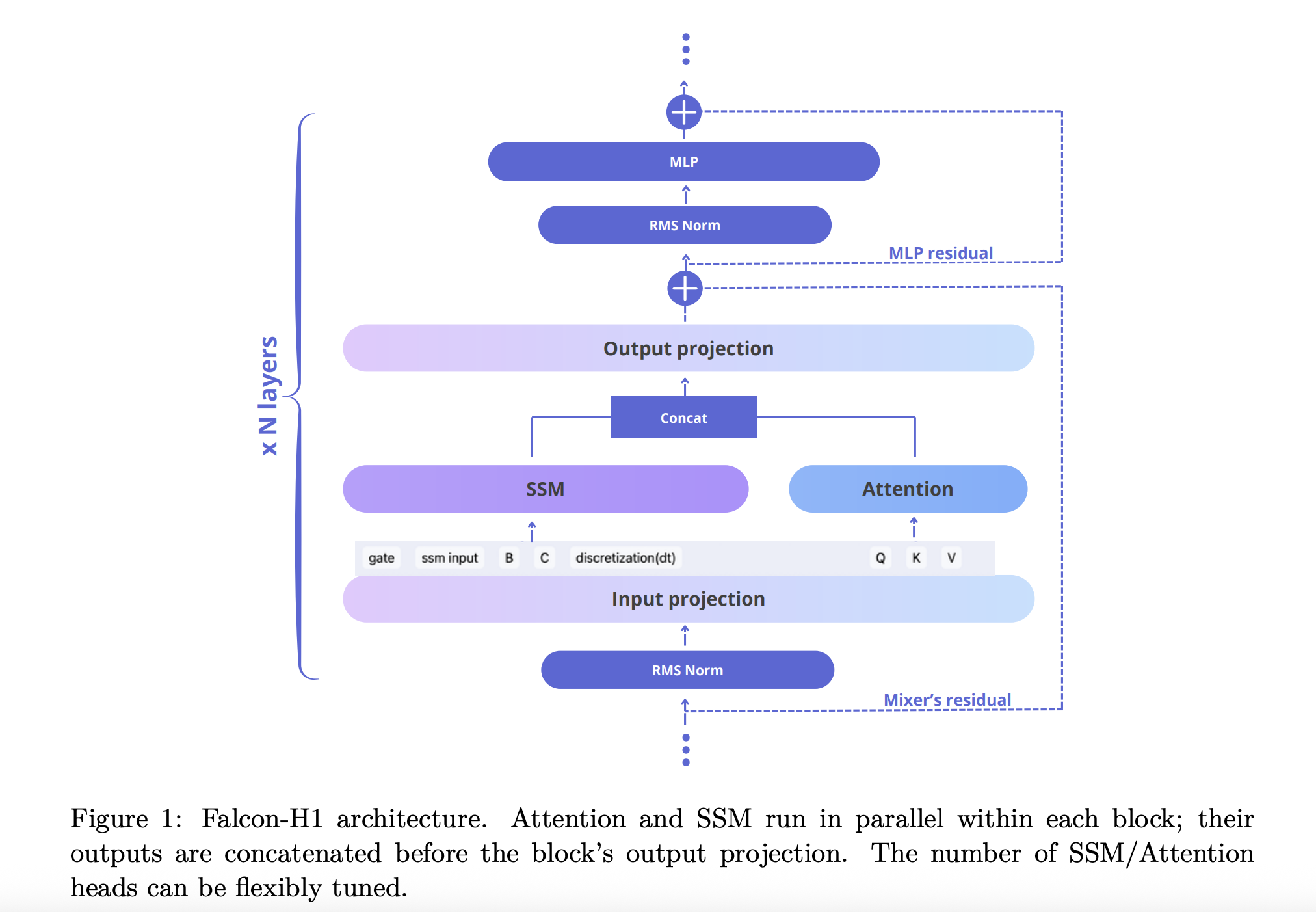
El informe técnico explica cómo Falcon-H1 adopta una novela arquitectura híbrida paralela donde tanto la atención como los módulos SSM operan simultáneamente, y sus salidas se concatenan antes de la proyección. Este diseño se desvía de la integración secuencial tradicional y proporciona la flexibilidad para ajustar la cantidad de atención y los canales SSM de forma independiente. La configuración predeterminada utiliza una relación 2: 1: 5 para los canales SSM, atención y MLP respectivamente, optimizando tanto la eficiencia como la dinámica de aprendizaje.

Para refinar aún más el modelo, Falcon-H1 explora:
- Asignación de canales: Las ablaciones muestran que el aumento de los canales de atención deteriora el rendimiento, mientras que el equilibrio de SSM y MLP producen ganancias robustas.
- Configuración de bloque: La configuración SA_M (semi-paralela con atención y SSM ejecutándose juntos, seguido de MLP) funciona mejor en pérdida de entrenamiento y eficiencia computacional.
- Frecuencia base de cuerda: Una frecuencia base inusualmente alta de 10^11 en incrustaciones posicionales rotativas (cuerda) demostró ser óptima, mejorando la generalización durante el entrenamiento de contexto a largo plazo.
- Compensación de ancho: Los experimentos muestran que los modelos más profundos superan a los más amplios bajo presupuestos de parámetros fijos. Falcon-H1-1.5B de profundidad (66 capas) supera a muchos modelos 3B y 7B.
Estrategia de tokenizador
Falcon-H1 utiliza una suite de tokenizador de codificación de pares de bytes personalizado (BPE) con tamaños de vocabulario que van desde 32k a 261K. Las opciones de diseño clave incluyen:
- División de dígitos y puntuación: Mejora empíricamente el rendimiento en el código y la configuración multilingüe.
- Inyección de token de látex: Mejora la precisión del modelo en los puntos de referencia de matemáticas.
- Soporte multilingüe: Cubre 18 idiomas y escalas a más de 100, utilizando fertilidad optimizada y bytes/métricas de tokens.
Estrategia de datos y datos de previación
Los modelos Falcon-H1 están entrenados en tokens hasta 18T desde un corpus de token 20T cuidadosamente curado, que comprende:
- Datos web de alta calidad (Filado Fineweb)
- Conjuntos de datos multilingües: Common Crawl, Wikipedia, ARXIV, OpenSubtitles y recursos seleccionados para 17 idiomas
- Código Corpus: 67 idiomas, procesados a través de la deduplicación de Minhash, los filtros de calidad de CodeBert y el scrubeo de PII
- Conjuntos de datos de matemáticas: Matemáticas, GSM8K y rastreos de látex en la casa mejorados
- Datos sintéticos: Reescritura de Corporos crudos utilizando diversos LLMS, más Qa de estilo de libros de texto de temas basados en 30k Wikipedia
- Secuencias de contexto largo: Mejorado a través de las tareas de razonamiento de relleno, reordenamiento y razonamiento sintético de hasta 256k tokens
Infraestructura y metodología de capacitación
La capacitación utilizó la parametrización de actualización máxima personalizada (µP), que admite escala suave a través de los tamaños del modelo. Los modelos emplean estrategias de paralelismo avanzadas:
- Paralelismo del mezclador (MP) y Paralelismo del contexto (CP): Mejorar el rendimiento para el procesamiento de contexto largo
- Cuantificación: Lanzado en variantes BFLOAT16 y de 4 bits para facilitar las implementaciones de borde

Evaluación y rendimiento
Falcon-H1 logra un rendimiento sin precedentes por parámetro:
- Falcon-H1-34b-Instructo supera o coincide con modelos a escala 70B como Qwen2.5-72B y LLAMA3.3-70B en tareas de razonamiento, matemáticas, seguimiento de instrucciones y multilingües
- Falcon-H1-1.5B de profundidad rivales 7B – 10B Modelos
- Falcon-H1-0.5b ofrece rendimiento de la era 72 de la era 2024
Los puntos de referencia abarcan tareas MMLU, GSM8K, Humaneval y contexto largo. Los modelos demuestran una fuerte alineación a través de SFT y optimización de preferencia directa (DPO).

Conclusión
Falcon-H1 establece un nuevo estándar para LLM de peso abierto mediante la integración de arquitecturas híbridas paralelas, tokenización flexible, dinámica de entrenamiento eficiente y capacidad multilingüe robusta. Su combinación estratégica de SSM y atención permite un desempeño inigualable dentro de los presupuestos prácticos de cómputo y memoria, por lo que es ideal tanto para la investigación como para la implementación en diversos entornos.
Mira el Papel y Modelos en la cara abrazada. No tener en cuenta Consulte nuestra página de tutoriales sobre AI Agent y Agentic AI para varias aplicaciones. Además, siéntete libre de seguirnos Gorjeo Y no olvides unirte a nuestro Subreddit de 100k+ ml y suscribirse a Nuestro boletín.

Michal Sutter es un profesional de la ciencia de datos con una Maestría en Ciencias en Ciencias de Datos de la Universidad de Padova. Con una base sólida en análisis estadístico, aprendizaje automático e ingeniería de datos, Michal se destaca por transformar conjuntos de datos complejos en ideas procesables.