
El equipo de AI de la PROFUMA ha lanzado Paso-paso 2 miniun modelo de lenguaje de audio grande de parámetros de parámetro 8B (LALM) que ofrece interacción de audio expresiva, fundamentada y en tiempo real. Liberado bajo el Licencia Apache 2.0este modelo de código abierto logra un desempeño de última generación en el reconocimiento de voz, la comprensión de audio y los puntos de referencia de conversación del habla, superando los sistemas comerciales como GPT-4O-Audio.

Características clave
1. Tokenización de texos de audio unificado
A diferencia de las tuberías ASR+LLM+TTS en cascaded, Step-Audio 2 se integra Modelado de token discreto multimodaldónde Tokens de texto y audio comparten una sola transmisión de modelado.
Esto habilita:
- Razonamiento sin interrupciones en texto y audio.
- Sobre la marcha Cambio de estilo de voz durante la inferencia.
- Consistencia en resultados semánticos, prosódicos y emocionales.
2. Generación expresiva y consciente de la emoción
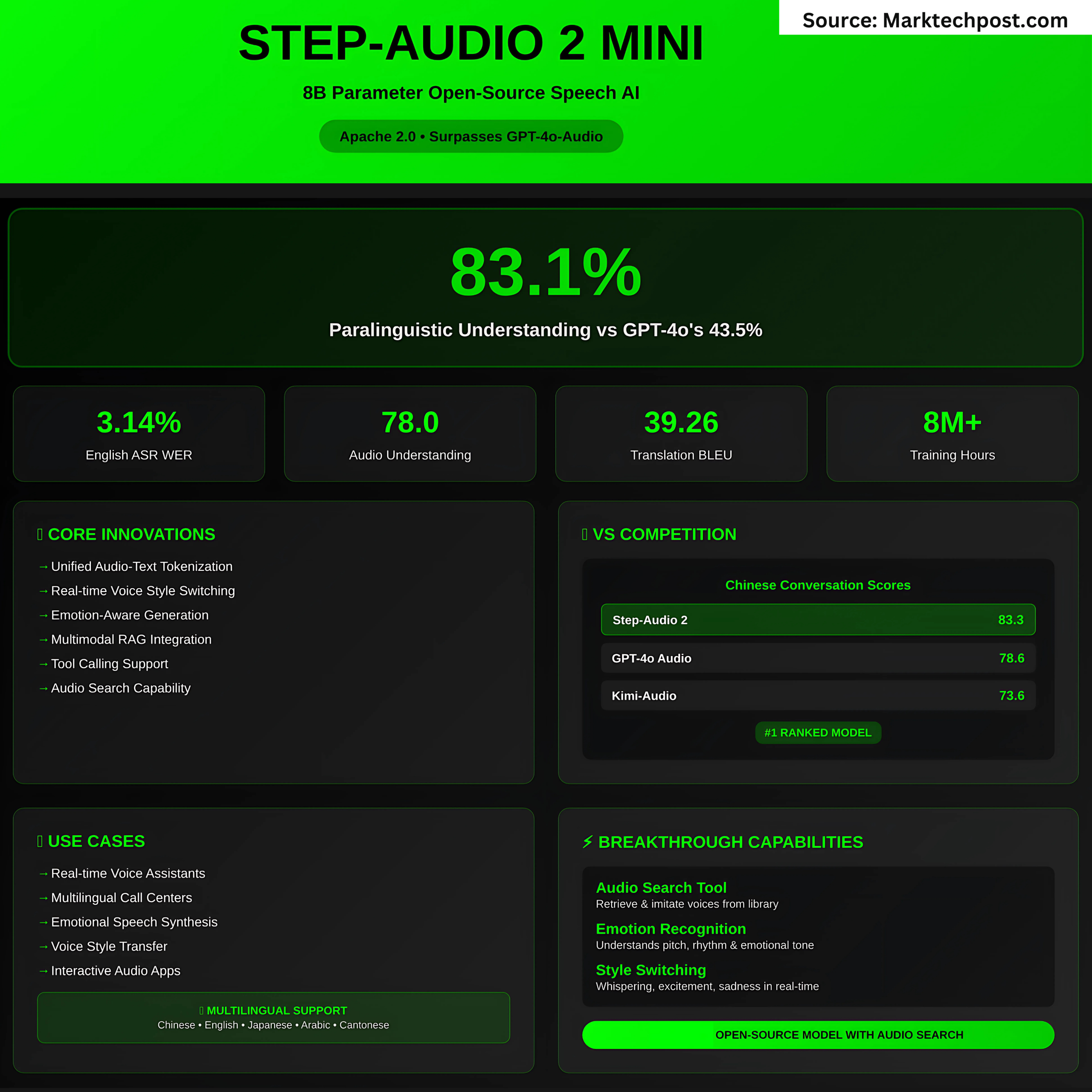
El modelo no solo transcribe el habla, se interpreta características paralingüísticas Como tono, ritmo, emoción, timbre y estilo. Esto permite conversaciones con tonos emocionales realistas como susurros, tristeza o emoción. Puntos de referencia en Stepeval-Audio-Paralingingle Mostrar el paso de paso de paso 2 83.1% de precisiónmucho más allá del audio GPT-4O (43.5%) y Qwen-AMNI (44.2%).
3. Generación de discursos de recuperación auggada
El paso de paso 2 incorpora trapo multimodal (generación de recuperación auggada):
- Integración de búsqueda web para la base objetiva.
- Búsqueda de audio—Una capacidad novedosa que recupera voces reales de una gran biblioteca y las fusiona en respuestas, habilitando Voz Timbre/Imitación de estilo a tiempo de inferencia.
4. Llamadas en herramientas y razonamiento multimodal
El sistema se extiende más allá de la síntesis del habla al apoyar Invocación de herramientas. Los puntos de referencia muestran que Step-Audio 2 coincide con LLMS textual en Selección de herramientas y precisión de los parámetrosmientras excepcionalmente en Llamadas de herramientas de búsqueda de audio—Un capacidad que no está disponible en LLMS de solo texto.
Capacitación y escala de datos
- Texto + Corpus de audio: 1.356t fichas
- Horas de audio: 8m+ horas reales y sintéticas
- Diversidad de los altavoces: ~ 50k Voces en todos los idiomas y dialectos
- Tubería previa a la altura: El plan de estudios de múltiples etapas que cubre ASR, TTS, traducción de voz a voz y síntesis conversacional marcada con emociones.
Este entrenamiento a gran escala permite que Step-Audio 2 Mini retenga un razonamiento de texto fuerte (a través de su Fundación QWEN2-Audio y Cosyvoice) mientras domina el modelado de audio de grano fino.
Puntos de referencia de rendimiento


Reconocimiento automático de voz (ASR)
- Inglés: Promedio WER 3.14% (GPT-4O se transcribe a un promedio de 4.5%).
- Chino: Promedio CER 3.08% (significativamente más bajo que GPT-4O y Qwen-AMNI).
- Robusto a través de dialectos y acentos.
Comprensión de audio (punto de referencia MMAU)
- Pase-Audio 2: 78.0 promedio, superando a Omni-R1 (77.0) y Audio Flamingo 3 (73.1).
- Más fuerte en Tareas de razonamiento de sonido y voz.
Traducción del habla
- Covost 2 (S2TT): Bleu 39.26 (más alto entre los modelos abiertos y cerrados).
- CVSS (S2ST): Bleu 30.87, por delante de GPT-4O (23.68).
Puntos de referencia conversacionales (URO-Bench)
- Conversaciones chinas: Mejor en general en 83.3 (básico) y 68.2 (Pro).
- Conversaciones en inglés: Competitivo con GPT-4O (83.9 vs. 84.5), muy por delante de otros modelos abiertos.
Conclusión
Paso-paso 2 mini Hace que la inteligencia del habla multimodal avanzada sea accesible para los desarrolladores y la comunidad de investigación. Al combinar Qwen2-audioLa capacidad de razonamiento con Tubería de tokenización de Cosyvoicey aumentar con Grounding basado en la recuperaciónStepfun ha entregado uno de los más capaces Open Audio LLMS.
Mira el PAPEL y Modelo en la cara abrazada. No dude en ver nuestro Página de Github para tutoriales, códigos y cuadernos. Además, siéntete libre de seguirnos Gorjeo Y no olvides unirte a nuestro Subreddit de 100k+ ml y suscribirse a Nuestro boletín.
Asif Razzaq es el CEO de MarktechPost Media Inc .. Como empresario e ingeniero visionario, ASIF se compromete a aprovechar el potencial de la inteligencia artificial para el bien social. Su esfuerzo más reciente es el lanzamiento de una plataforma de medios de inteligencia artificial, MarktechPost, que se destaca por su cobertura profunda de noticias de aprendizaje automático y de aprendizaje profundo que es técnicamente sólido y fácilmente comprensible por una audiencia amplia. La plataforma cuenta con más de 2 millones de vistas mensuales, ilustrando su popularidad entre el público.