
Introducción: el surgimiento de los agentes de la GUI
La informática moderna está dominada por interfaces gráficas de usuarios en dispositivos: móvil, escritorio y web. La automatización de tareas en estos entornos se ha limitado tradicionalmente a macros con guión o reglas frágiles de ingeniería a mano. Los avances recientes en los modelos en idioma de la visión ofrecen la tentadora posibilidad de agentes que pueden comprender las pantallas, razonar sobre las tareas y ejecutar acciones al igual que los humanos. Sin embargo, la mayoría de los enfoques se han basado en modelos de código cerrado, de caja negra o han tenido problemas con la generalización, la fidelidad del razonamiento y la robustez multiplataforma.
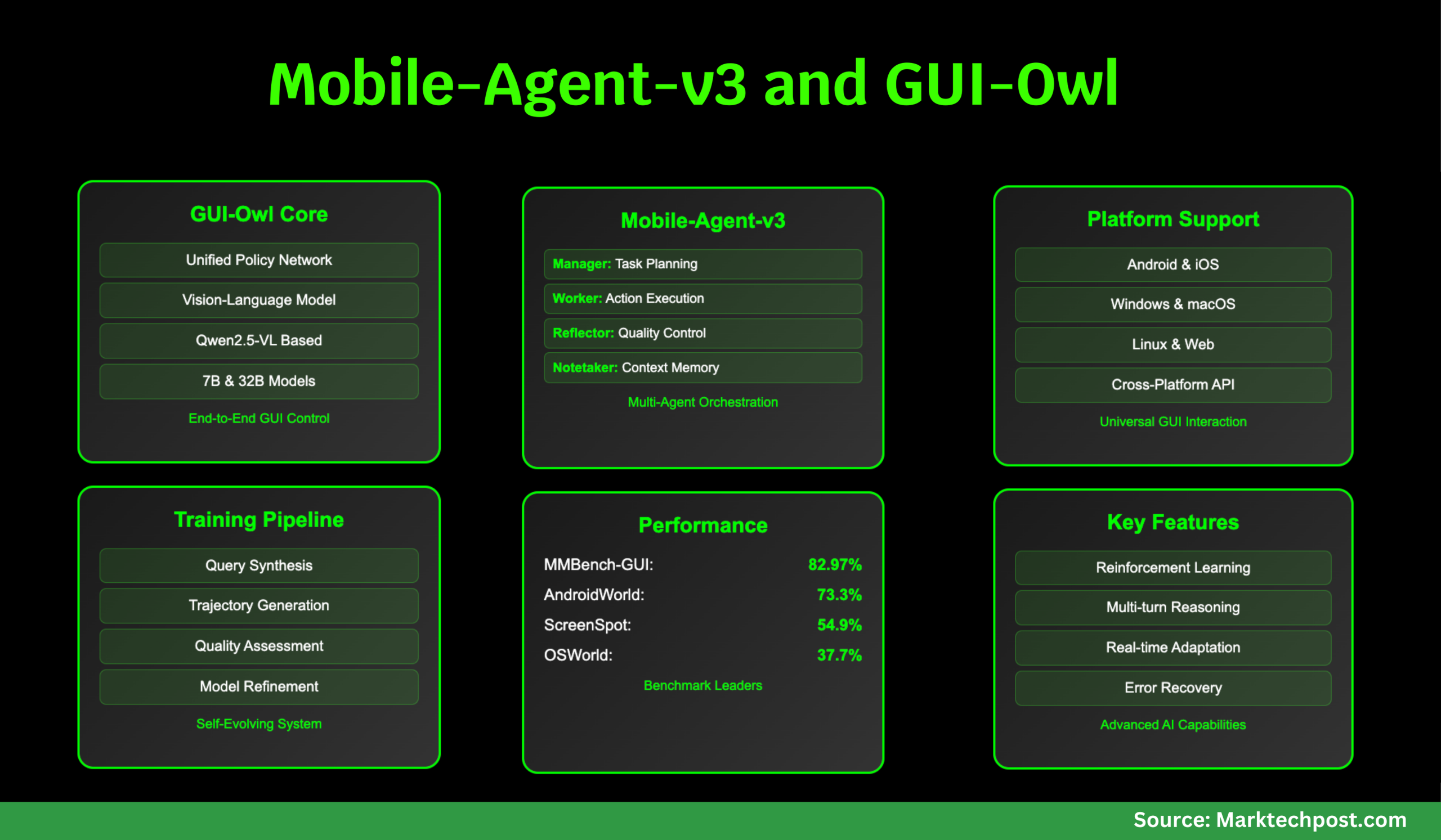
Un equipo de investigadores de Alibaba Qwen introduce Guijar y Móvil-agente-v3 que estos desafían de frente. Gui-Owl es un modelo de agente multimodal nativo de extremo a extremo, basado en QWEN2.5-VL y ampliamente posttrado en datos de interacción GUI a gran escala y diversos. Unifica la percepción, la base, el razonamiento, la planificación y la ejecución de la acción dentro de una sola red de políticas, lo que permite una interacción sólida multiplataforma y un razonamiento explícito múltiple. El marco móvil-agente-v3 aprovecha GUI-OWN como un módulo fundamental, que orquesta múltiples agentes especializados (gerente, trabajador, reflector, notable) para manejar tareas complejas de horizonte larga con planificación dinámica, reflexión y memoria.

Arquitectura y capacidades centrales
GUI-OWL: el modelo fundamental
Gui-Owl está diseñado desde cero para manejar la heterogeneidad y el dinamismo de los entornos de GUI del mundo real. Se inicializa desde Qwen2.5-VL, un modelo de lenguaje de visión de última generación, pero sufre una amplia capacitación adicional en conjuntos de datos GUI especializados. Esto incluye toma de tierra (Localización de elementos de interfaz de usuario de consultas de lenguaje natural), planificación de tareas (Desglosar instrucciones complejas en pasos procesables), y semántica de acción (Comprender cómo las acciones afectan al estado de la GUI). El modelo se ajusta a través de una combinación de aprendizaje supervisado y aprendizaje de refuerzo (RL), con un enfoque en alinear sus decisiones con el éxito de la tarea del mundo real.
Innovaciones clave en Gui-Owl:
- Red de política unificada: A diferencia de la investigación previa que separa la percepción, la planificación y la ejecución en módulos disjuntos, GUI-OWL integra estas capacidades en una sola red neuronal. Esto permite una toma de decisiones multifiratorio perfecta y un razonamiento intermedio explícito explícito, muy importante para manejar la ambigüedad y la variabilidad de las GUI reales.
- Infraestructura de entrenamiento escalable: El equipo creó un entorno virtual basado en la nube que abarca Android, Ubuntu, MacOS y Windows. Esta tubería de “producción de trayectoria de GUI autoevolución” genera datos de interacción de alta calidad al tener GUI-OWN y Mobile-Agent-V3 interactúa con dispositivos virtuales, luego juzgando rigurosamente la exactitud de las trayectorias. Las trayectorias exitosas se utilizan para una mayor capacitación, creando un ciclo virtuoso de mejora.
- Diversa síntesis de datos: Para enseñar al modelo de base y razonamiento sólidos, el equipo de investigación emplea una variedad de estrategias de síntesis de datos: sintetizar tareas de base de elementos de la interfaz de usuario de los árboles de accesibilidad y capturas de pantalla rastreadas, destilando el conocimiento de planificación de tareas de las trayectorias históricas y grandes LLM pretrésiadas y generando datos semánticos de acción al tener el modelo predicto el efecto de las acciones que se dan a las pantallas de antes y a los seguidores.
- Alineación de aprendizaje de refuerzo: GUI-OWL se refina aún más a través de un marco RL escalable que admite una capacitación totalmente asincrónica y una nueva “optimización de políticas relativas de trayectoria” (TRPO). TRPO asigna crédito a través de secuencias de acción largas y de longitud variable, un avance crítico para las tareas de GUI donde las recompensas son escasas y solo están disponibles al finalizar la tarea.

Mobile-agent-v3: coordinación de múltiples agentes
Mobile-Agent-V3 es un marco de agente de uso general diseñado para abordar flujos de trabajo complejos, de múltiples pasos y de aplicación cruzada. Descumia las tareas en subggoal, actualiza dinámicamente los planes basados en la retroalimentación de la ejecución y mantiene la memoria contextual persistente. Las coordenadas del marco Cuatro agentes especializados:
- Agente del gerente: Descompone las instrucciones de alto nivel en los subconocentes, actualizando dinámicamente el plan en función de los resultados y la retroalimentación.
- Agente de trabajadores: Ejecuta el subggoal procesable más relevante dado el estado GUI actual, los comentarios anteriores y las notas acumuladas.
- Agente reflector: Evalúa el resultado de cada acción, comparando las transiciones estatales previstas y reales para generar comentarios de diagnóstico.
- Agente de notaker: Persiste información crítica (por ejemplo, códigos, credenciales) a través de los límites de la aplicación, lo que permite tareas de oraciones largas.
Capacitación y tuberías de datos
Un gran cuello de botella en el desarrollo de agentes de GUI es la falta de datos de entrenamiento escalables de alta calidad. Los enfoques tradicionales se basan en una costosa anotación manual, que no se escala a la diversidad y el dinamismo de las GUI reales. El equipo de GUI-OWN se dirige a esto con un tubería de producción de datos de autoevolución:
- Generación de consultas: Para aplicaciones móviles, un gráfico acíclico dirigido por humano (DAG) modela flujos de navegación realistas y pares de valor de ranura para entradas de los usuarios. LLMS sintetizan las instrucciones naturales de estas rutas, que se refinan y validan aún más contra las interfaces de aplicaciones reales.
- Generación de trayectoria: Dada una consulta, GUI-OWN o Mobile-Agent-V3 interactúa con un entorno virtual para producir una trayectoria, una secuencia de acciones y transiciones de estado.
- Juicio de corrección de la trayectoria: Un sistema crítico de dos niveles evalúa cada paso (¿la acción tenía el efecto previsto?) Y la trayectoria general (¿la tarea tuvo éxito?). Esto utiliza razonamiento textual y multimodal, con juicios finales basados en consenso.
- Síntesis de orientación: Para consultas desafiantes, el sistema sintetiza la guía paso a paso de las trayectorias exitosas (humanas o modelo), ayudando al agente a aprender de ejemplos positivos.
- Entrenamiento iterativo: Se agregan trayectorias exitosas recientemente generadas al conjunto de capacitación, y el modelo se reacunta, cerrando el bucle en la superación personal.

Benchmarking y rendimiento
GUI-OWN y Mobile-Agent-V3 se evalúan rigurosamente en un conjunto de puntos de referencia de automatización de GUI, que cubren la conexión a tierra, la toma de decisiones de un solo paso, la respuesta de preguntas y la finalización de la tarea de extremo a extremo.
Inmediada y comprensión de la interfaz de usuario
En tareas de base, localizar elementos de la interfaz de usuario de consultas de lenguaje natural,GUI-OWN-7B supera todos los modelos de código abierto de tamaño comparable, y GUI-OWN-32B supera incluso modelos propietarios como GPT-4O y Claude 3.7. Por ejemplo, en el Mmbench-gui l2 Benchmark (que cubre Windows, MacOS, Linux, iOS, Android y Web), GUI-OWN-7B obtiene 80.49, mientras que GUI-OWN-32B logra 82.97, ambos muy por delante de la competencia. En Screenspot Proque se centra en interfaces complejas de alta resolución, puntajes GUI-OWN-7B 54.9, superando significativamente la UI-TARS-72B y QWEN2.5-VL-72B. Estos resultados demuestran que las capacidades de conexión a tierra de GUI-OWN son amplias y profundas, manejando todo, desde simples clics de botones hasta localización de texto de grano fino.
Comprensión de la GUI integral y toma de decisiones de un solo paso
Mmbench-gui L1 Evalúa la comprensión de la interfaz de usuario y la toma de decisiones de un solo paso a través de la respuesta de la pregunta. Aquí, los puntajes de GUI-OWN-7B 84.5 (fácil), 86.9 (medio) y 90.9 (duro)superando con mucho todos los modelos existentes. Esto indica no solo una percepción precisa, sino un razonamiento robusto sobre los estados y acciones de la interfaz. En Control de Androidque se centra en las decisiones de un solo paso en contextos pre-anotados, GUI-OWL-7B logra 72.8, el más alto entre los modelos 7B, mientras que GUI-OWN-32B alcanza 76.6, superando incluso los modelos abiertos y propietarios más grandes.
Capacidades de extremo a extremo y de agente múltiple
La prueba real de un agente GUI es su capacidad para completar tareas reales de varios pasos en entornos interactivos. Androidworld y Osworld son dos de estos puntos de referencia, donde los agentes deben navegar de forma autónoma y sistemas operativos para lograr las instrucciones del usuario. GUI-OWN-7B puntajes 66.4 en AndroidWorld y 34.9 en Osworld, mientras que Móvil-agente-v3 (con gui-owal como su núcleo) logra 73.3 y 37.7respectivamente, un nuevo estado del arte para marcos de código abierto. El diseño de múltiples agentes resulta especialmente efectivo en tareas propensas a errores de horario largo, ya que los agentes de reflector y gerente permiten la replanación dinámica y la recuperación de los errores.
Integración del mundo real
El equipo de investigación también evaluó el desempeño de Gui-Owl como el “cerebro” dentro de marcos de agente establecidos como Agente móvil-E (Android) y Agente-S2 (de oficina). Aquí, Gui-Owl-32b logra un éxito del 62.1% en AndroidWorld y 48.4% en un subconjunto desafiante de Osworld, superando significativamente todas las líneas de base. Esto subraya el valor práctico de GUI-OWN como un módulo plug-and-play para diversos sistemas de agentes.
Implementación del mundo real
GUI-OWL admite un espacio de acción rico y específico de la plataforma. En los dispositivos móviles, esto incluye clics, prensas largas, golpes, entrada de texto, botones del sistema (atrás, inicio, etc.) y lanzamiento de aplicaciones. En el escritorio, las acciones abarcan los movimientos del mouse, los clics, los arrastre, los pergaminos, la entrada del teclado y los comandos específicos de la aplicación. Las acciones se traducen en comandos de dispositivos de bajo nivel (ADB para Android, Pyautogui para escritorio), lo que hace que el marco se desplume fácilmente en entornos reales.
El proceso de razonamiento y decisión del agente es transparente: para cada paso, observa la pantalla, recuerda el historial comprimido, las razones de la próxima acción, resume su intención y se ejecuta. Este razonamiento intermedio explícito no solo mejora la robustez, sino que también permite la integración en sistemas de múltiples agentes más grandes, donde diferentes “roles” (por ejemplo, planificador, ejecutor, crítico) pueden especializarse y colaborar.
Conclusión: hacia los agentes de la GUI de uso general
GUI-OWN y Mobile-Agent-V3 representan un gran salto hacia agentes de GUI autónomos de uso general. Al unificar la percepción, la base, el razonamiento y la acción en un solo modelo, y al construir una tubería de capacitación escalable y de mejor momento, el equipo de investigación ha logrado rendimiento de última generación en entornos móviles y de escritorio, superando incluso los modelos propietarios más grandes en puntos de referencia clave.
Mira el PAPEL y Página de Github. No dude en ver nuestro Página de Github para tutoriales, códigos y cuadernos. Además, siéntete libre de seguirnos Gorjeo Y no olvides unirte a nuestro Subreddit de 100k+ ml y suscribirse a Nuestro boletín.
Asif Razzaq es el CEO de MarktechPost Media Inc .. Como empresario e ingeniero visionario, ASIF se compromete a aprovechar el potencial de la inteligencia artificial para el bien social. Su esfuerzo más reciente es el lanzamiento de una plataforma de medios de inteligencia artificial, MarktechPost, que se destaca por su cobertura profunda de noticias de aprendizaje automático y de aprendizaje profundo que es técnicamente sólido y fácilmente comprensible por una audiencia amplia. La plataforma cuenta con más de 2 millones de vistas mensuales, ilustrando su popularidad entre el público.